
ZE-3 專題報告
指導教授:邱昭彰 教授
專題學生:汪文豪
學號:1071710
研究問題
合成身分詐欺問題
以美國現況為例,使用合成身分手法之詐欺者會將被害者的SSN(Social Security Number,以下簡稱SSN)及其他真實資料或是假資料結合(圖一),以此手法創建一個全新身份,並以此身份騙取金融機構進行授信活動,申請信用卡、貸款等金融服務。詐欺者前期會如同正常使用者一般的使用金融服務以培養信用紀錄,等其信用紀錄最大化後,即宣告破產,進而使銀行產生呆帳。而受到合成身分竊取資料之受害者近乎都是兒童、老人與遊民等,平常並不會關心自己信用紀錄是否有被建立,待於兒童成年後申請貸款才發現自己身份遭人盜用。

圖一、合成身份詐欺示意圖
圖片來源:Improving First-Party Bank Fraud Detection with Graph Databases - Neo4j Graph Database Platform
過往研究問題
過往在2017年就已有多份文獻指出有合成身分詐欺手法,但在2019年卻仍舊有研究者採用傳統數據集進行詐欺檢測研究。然而在同一年時美聯儲針對其合成身分詐欺問題發布其犯罪手法白皮書。由此可得知此一詐欺手法不減反增,更證明目前詐欺檢測方法有改善之空間。
研究架構示意圖
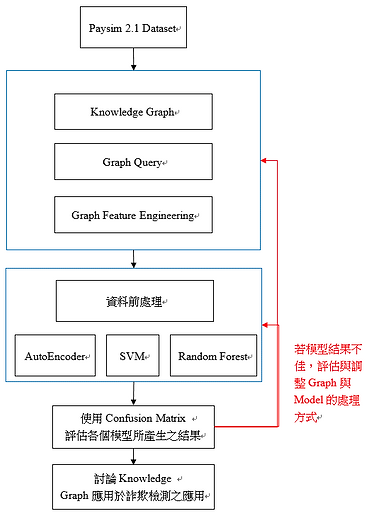
圖三、研究架構示意圖
核心技術
知識圖譜(Knowledge Graph, KG)
Google在2012年提出知識圖譜,應用圖結構描述世界萬物的連結,Google將知識圖譜運用於搜尋引擎,使搜尋結果更為正確,以及藉由知識圖譜的連結性,使Google的搜尋引擎讓使用者可以搜尋到許多意想不到的相關事物與摘要,從Stanford University所開的知識圖譜教材中,可看到有不同的知識圖譜相關演算法可以進行關於知識圖譜之資料的萃取,擴充其可用的資料維度。從這點來看,我們可以知道知識圖譜在資料連結性之間的應用其實相當強大,我們甚至可以推測其萃取出來之資料特徵維度是可以幫助筆者進行詐欺檢測。因此在本次研究中,應用知識圖譜的觀念進行合成身分的詐欺檢測理應是適合不過。從圖一可看到資料中節點彼此之間的連結,透過將資料以圖結構進行呈現,並挖掘出圖的知識,拿到更深層的資料見解,相信將會提升詐欺檢測模型其檢測的效果。
AutoEncoder
如下圖所示AutoEncoder最主要擁有三個核心架構(Encoder, Bottleneck, Decoder),利用Encoder將其輸入資料降至低維度的Bottleneck(即下圖架構圖之中間的h(xi))再利用其Decoder升至原輸入資料維度,讓輸出資料能夠越接近輸入資料越好(即Reconstruct Error越小越好)。由於其Encoder與Decoder的特性,通常可用作降維、異常檢測、降噪、圖結構社區檢測等多種應用,而其研究在過往皆有良好的表現成效。
本研究將應用此深度學習模型於詐欺檢測案例,將歸類於正常的資料之資料維度,用以訓練其Encoder與Decoder,讓模型學會正常的資料重構模式,照理來說最後模型將會學會如何重構正常資料的模式,此時當異常資料丟入訓練的模型時,資料的重構即會發生問題,導致Reconstruct Error加大,此時我們就可以透過這種方法,偵測出異常資料。

圖二、AutoEncoder架構示意圖
圖片來源: Zou, J., Zhang, J., & Jiang, P. (2019). Credit card fraud detection using autoencoder neural network. arXiv preprint arXiv:1908.11553.
綜合結果比較
使用知識圖譜進行資料建模的益處
當取消從知識圖譜處理得來的資料維度特徵後,將會看到詐欺資料(Mule)之Recall率大幅下降,每套模型均不超過五成的詐欺資料檢測率。從這點來看我們可以清楚的得知在某些情境下,若能以知識圖譜的角度看待資料,萃取其圖譜特徵,不但可以擴增資料維度,更可以有效訓練其模型,並有效提升其檢測成效。
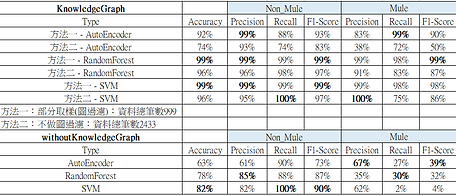
圖四、檢測成效比較表